
Google ist vor Kurzem der Nachweis der sogenannten „Quanten-Überlegenheit“ gelungen. Die Quanten-Überlegenheit ist der große Meilenstein in der Entwicklung aktueller Quantencomputer. Die Quanten-Überlegenheit markiert den Punkt in der Computer-Geschichte, an dem ein Quantencomputer erstmals nachweislich alle herkömmlichen Supercomputer für ein bestimmtes Problem überflügelt. Ich erläutere Ihnen alle Details, die spannenden Hintergründe und gebe genaue Erklärungen zu diesem wohl bahnbrechenden Ereignis.
Inhalt
- 1 Eine Sternstunde von Wissenschaft und Technik
- 2 Googles Nachweis der Quanten-Überlegenheit: Ein Gerücht bestätigt sich
- 3 Die Entwicklung der ersten Quantencomputer
- 4 Die NISQ-Ära der Quantencomputer
- 5 Was ist die Quanten-Überlegenheit?
- 6 Welche Bedeutung hat Googles Nachweis der Quanten-Überlegenheit?
- 7 Googles Weg zum Nachweis der Quanten-Überlegenheit
- 8 Googles Team formiert sich
- 9 Googles Quantencomputer „Sycamore“
- 10 Die Rechenaufgabe: „Random Quantum Circuit Sampling“
- 11 Ein reales Anwendungsgebiet: Quantenzertifizierte Zufallszahlen
- 12 Das Finale: Googles Nachweis der Quanten-Überlegenheit
- 13 Was ist nun mit IBMs Einwand?
- 14 Warum kein Supercomputer diese Berechnung durchführen kann
- 15 Ein verpasster „Mond-Lande-Moment“ für Googles Team?
- 16 Fußnoten
Eine Sternstunde von Wissenschaft und Technik
Wissenschaft, das bedeutet in der Regel ein Ringen nach Erkenntnis in mühevoller Detailarbeit, das Wegstecken von Misserfolgen, dem Überdenken und dem Weitermachen. Wissenschaft bedeutet aber auch immer wieder kleine Erfolge feiern, zusammen mit einer eingefleischten Schar von gleichgesinnten Kolleginnen und Kollegen. Erfolge, die das Große und Ganze wieder ein kleines Stück nach vorne gebracht haben, in der Regel unbemerkt von der breiten Masse.
Und dann gibt es die sehr seltenen, die richtig großen Momente: Die Sternstunden von Wissenschaft und Technik. Der letzte große Baustein in einer langen Kette von vorangegangenen Ereignissen, der so mächtig ist, dass er einen ganzen neuen Wissenszweig in das Licht der Öffentlichkeit zwingt.
Dem Internet-Konzern Google so ein Paukenschlag zuletzt gelungen ist:
Das „AI Quantum“-Team des Tech-Riesens hat vor Kurzem die sogenannte „Quanten-Überlegenheit“ nachgewiesen.
Googles Nachweis der Quanten-Überlegenheit: Ein Gerücht bestätigt sich
Erste handfeste Anzeichen hierfür wurden bereits im Juni publik. Das Online-Magazin Quantamagazine berichtete über eine ominöse Berechnung, für die die enormen Rechen-Ressourcen des Tech-Riesen angezapft werden mussten. Im Juli gab dann das Forschungszentrum Jülich eine Pressemitteilung über eine neue beschlossene Partnerschaft mit Google heraus i. Später stellte sich heraus, dass auch der Jülicher Supercomputer eine gewisse Rolle bei Google Nachweis spielte.
Ende September stellte die NASA, einer von Googles Partnern in der Sache, eine vertrauliche Vorabversion von Googles Forschungsarbeit als Download bereit. Dies geschah vermutlich für interne Zwecke, nur für kurze Zeit und in einem gut versteckten Bereich auf der Webseite. Allerdings nicht versteckt genug für Googles eigene Suchmaschine: Der automatisierte Google-„Crawler“ war kurz nach der Veröffentlichung auf das Dokument aufmerksam geworden und hatte es eigenhändig weiter verteilt.
Die Meldung machte schnell die Runde und mehrere Nachrichtenseiten berichteten darüber.
Schließlich zog Google nach und stellte das besagte Dokument mit dem Titel „Quantum Supremacy Using a Programmable Superconducting Processor“ selbst zum Download bereit (zusammen mit einem Zusatzartikel) ii. Vorerst allerdings noch vollkommen unkommentiert, da sich die Arbeit zu diesem Zeitpunkt in der „Peer-Review“-Phase befand.
Es spricht für Google, dass der Konzern seine wohl bahnbrechenden Ergebnisse nicht vorschnell bekanntgab, sondern den ordentlichen wissenschaftlichen Prüfprozess abwartete.
Gestern erfolgte nun die offizielle Veröffentlichung in der Fachzeitschrift „Nature“ iii.
Im Zentrum der Arbeit steht der bisher unbekannte Quantencomputer „Sycamore“ von Google und eine Berechnung, die auf den aktuell schnellsten Supercomputern vermutlich 10 000 Jahre dauern würde: Sycamore benötigte dafür lediglich 200 Sekunden.
Anfang dieser Woche würzte die IBM-Gruppe für Quantencomputer die aktuellen Entwicklungen mit einem zusätzlichen interessanten Detail: Mit ihrem verbesserten Simulationsverfahren hätte der schnellste Supercomputer vermutlich nur 2 ½ Tage benötigt.
Im Folgenden erfahren Sie alle Details und die spannenden Hintergründe zu diesem, wohl trotzdem, bahnbrechenden Ereignis.
Die Entwicklung der ersten Quantencomputer
Im tiefsten Inneren funktioniert die Natur nicht nach unseren Alltagsgesetzen, sondern nach den rätselhaften Gesetzen der Quantenwelt. Aus diesem Grund stoßen herkömmliche Computer schnell an ihre Grenzen, wenn es darum geht Naturprozesse im atomaren Maßstab zu berechnen. Vor über 30 Jahren hinterließ der legendäre Physiker Richard Feynman der Wissenschaftswelt ein visionäres aber nahezu aussichtsloses Vermächtnis: Erst wenn es uns gelänge Computer zu konstruieren, die auf eben dieser Quantenlogik basieren, könnten wir die Natur letztendlich simulieren und grundlegend berechnen.
Nachdem diese Idee einmal geboren war, nahm das Thema schnell Fahrt auf. Der erste riesige Paukenschlag erfolgte, als der Mathematiker Peter Shor 1994 nachwies, dass die als bombensicher geglaubte Verschlüsselung im Internet mit einem sehr großen Quantencomputer in Sekundenschnelle geknackt werden könnte (nur das kein falscher Eindruck entsteht: Shors Algorithmus spielt bei Googles Nachweis der Quanten-Überlegenheit keine Rolle).
Die technischen Hürden für die weitere Entwicklung waren und sind nach wie vor gewaltig. Es dauerte nahezu 20 Jahre, bis der erste sehr experimentelle Mini-Quantencomputer in einer Forschungseinrichtung gebaut wurde.
Die NISQ-Ära der Quantencomputer
Mit der Zeit erkannten die Tech-Riesen IBM, Google, Microsoft und Co das riesige Potential der neuen Technologie. Sie starteten Kooperationen mit Forschergruppen, warben hochkarätige Wissenschaftler an und stiegen selbst in die Entwicklung der Quantencomputer ein.
Als Resultat stehen jetzt erste Quantencomputer-Angebote von Tech-Firmen in der Cloud bereit. Verfügbar für jedermann. Den aktuellen Stand beschreibe ich in meinem Artikel „Welche Quantencomputer gibt es jetzt schon?“
Aktuelle Quantencomputer haben noch eine sehr kleine Größe von bis zu 20 „Qubits“, den Quanten-Bits. Genauso wie herkömmliche Bits können Qubits die Werte 0 oder 1 annehmen. Darüber hinaus können sie sich aber auch in „überlagerten“ Zuständen von sowohl 0 als auch 1 befinden.
Um dies zu veranschaulichen, verwende ich auf „quantencomputer-info.de“ eine Qubit-Darstellung, die gegenüber der Lehrbuchdarstellung vereinfacht ist aber dem Kern bereits sehr nahe kommt: Ein einfacher Zeiger in einer Ebene. Folgendes Qubit ist zum Beispiel zu gleichen Teilen sowohl im Zustand 0 als auch im Zustand 1.
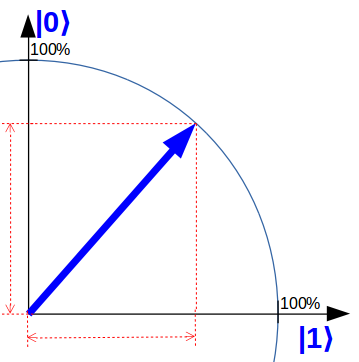
Im Verlauf einer Quantenrechnung werden die Qubits „gedreht“ und am Ende ausgemessen. Durch diese Messung „entscheiden“ sich die Qubits jeweils für einen der beiden Werte: 0 oder 1. Diese Entscheidung geschieht rein zufälligund unterliegt den Gesetzen der Quantenmechanik.
Der eigentliche Clou dabei ist Folgender: Ein Quantencomputer verdoppelt seine potentielle Rechenstärke mit jedem zusätzlichen Qubit. Also exponentiell!
Noch viel mehr über die fundamentalen Unterschiede zwischen einem herkömmlichen Computer und einem Quantencomputer erfahren Sie in meinem Einstiegsartikel „Der unglaubliche Quantencomputer einfach erklärt“.
Die aktuellen Quantencomputer befinden sich noch in der sogenannten „NISQ-Ära“. Das steht für „Noisy Intermediate Scale Quantum“, also fehleranfällige Quantencomputer mit einer „mäßigen“ Größe von wenigen Hundert „Qubits“, perspektivisch gesehen.
Was ist die Quanten-Überlegenheit?
Damit Sie einen Eindruck davon bekommen: Der Shor-Algorithmus würde vermutlich hunderttausende von Qubits und Millionen von Rechenoperationen benötigen.
Eine große Frage treibt die Quantencomputer-Szene deshalb an:
Kann man jetzt schon eine Berechnung auf einem Quantencomputer durchführen, die
-
-
- einen echten praktischen Nutzen hat und
- die kein herkömmlicher Supercomputer jemals durchführen könnte?
-
Mit den Jahren wurden tatsächlich mehrere Quanten-Algorithmen mit praktischem Nutzen entwickelt, die selbst auf aktuellen Quantencomputern laufen können. Das Problem dabei ist: Diese Berechnungen könnten selbst von einem normalen Laptop spielend durchgeführt werden.
Mittlerweile ist klar, dass die Suche nach einem solchen Algorithmus einfach zu groß ist.
Deshalb konzentriert man sich seit Jahren auf Punkt 2: Kann ein aktueller Quantencomputer selbst den größten Supercomputer in irgendeiner Berechnung überflügeln, egal ob sie irgendeinen praktischen Nutzen hat oder nicht?
Und genau das ist die Quanten-Überlegenheit.
John Preskill vom California Institute of Technology (Caltech), einer der führenden Wissenschaftler in der Quantencomputer-Forschung, hatte die Schallmauer für die Quanten-Überlegenheit bzw. die „Quantum Supremacy“ 2012 berechnet iv und damit auch den Startschuss für ein technologisches Wettrennen gegeben. Ab einer Quantencomputergröße von 49 oder 50 Qubit sollte ein Quantencomputer in der Lage sein, gewisse Berechnungen sehr viel schneller auszuführen als jeder herkömmliche Supercomputer. Ein Quantencomputer ab dieser Größe müsste in der Lage sein, seinen ihm eigenen und tief verwurzelten Geschwindigkeitsvorteil auszuspielen.
Welche Bedeutung hat Googles Nachweis der Quanten-Überlegenheit?
Für den Nachweis der Quanten-Überlegenheit benötigt man also nur eine einzige Berechnung.
Auf der einen Seite klingt dieser Anspruch etwas lächerlich. Nach dem Motto „Wir hängen die Kirschen mal so richtig niedrig, dass wir sie auch ja erreichen werden“. Von echter „Überlegenheit“ kann also keine Rede sein. In allen anderen Rechenaufgaben sind herkömmliche Computer den aktuellen Quantencomputern weiterhin meilenweit überlegen.
Auf der anderen Seite klingt das Vorhaben aber auch absolut absurd: Selbst ein normaler Laptop arbeitet mit Milliarden von herkömmlichen Bits und mehreren Prozessorkernen. Ein Supercomputer wiederum bewegt sich in Sphären, die mehrere Größenordnungen darüber liegen. Seit vielen Jahrzehnten arbeiten die Computerwissenschaften und die IT daran, Computerprogramme noch besser, noch schneller zu machen. Den Erfolg dieser Entwicklungen können wir überall um uns herum, in unserer digitalisierten Welt bestaunen.
Es ist deshalb vollkommen abwegig anzunehmen, dass man irgendeine neue Art von programmierbarer, universeller Rechenmaschine konstruieren könnte, mit gerade mal ein paar Dutzend „Irgendetwas-Bits“, die auch nur eine einzige Aufgabe fundamental besser erledigen könnte, als die allerbesten unserer altbewährten Computer.
Dahinter verbirgt sich letztendlich eine „uralte“ Hypothese aus der Gründerzeit der theoretischen Informatik: Die „Erweiterte Church-Turing-These“. Sie besagt gerade das Gegenteil: Jede Art von universeller Rechenmaschine kann von einem herkömmlichen Computer effizient nachgeahmt bzw. simuliert werden, und die Rückrichtung gilt genauso v. Oder einfacher ausgedrückt: Wir können zwar unsere Rechentechniken und unsere Computer immer wieder weiter beschleunigen, die Natur unserer Rechenmaschinen können wir aber nicht mehr fundamental verbessern.
Wer die Quanten-Überlegenheit nachweist, hat also insbesondere die berühmte Erweiterte Church-Turing-These widerlegt!
Das ist ein Fakt.
Kommen wir auch nochmal auf die Sternstunden-Sache zurück: Oft genug lag das Wunder solcher Momente in dem Nachweis des generell Machbaren.
Nehmen wir z.B. den Jungfernflug der Wright-Brüder: Am 17. Dezembers 1903 flog Orville Wright den ersten Flug einer navigierfähigen Propeller-Maschine: 12 Sekunden lang und 37 Meter weit. Also sehr überschaubar und eigentlich nicht der Rede wert. Trotzdem ist dieser Moment in die Geschichtsbücher eingegangen vi. Bereits Ende 1905 flogen die Brüder fast 40 Minuten lang und 40 Kilometer weit.
Wir müssen abwarten, wie es sich mit den Quantencomputern verhält …
Googles Weg zum Nachweis der Quanten-Überlegenheit
Für den Nachweis der Quanten-Überlegenheit mussten die Wissenschaftler von Googles Team fünf äußerst schwierige Aufgaben bewältigen:
-
-
- Sie mussten einen universellen Quantencomputer mit etwa 50 Qubit konstruieren, der verlässlich in der Lage ist, beliebige Quantenprogramme korrekt auszuführen.
- Sie mussten eine Rechenaufgabe finden, die speziell auf diesen Quantencomputer zugeschnitten ist und die tatsächlich alle seine Qubits und alle Standard-Operationen für Quantencomputer ausnutzt (jede andere Aufgabe wäre vermutlich effizient auf herkömmlichen Computern lösbar).
- Sie mussten diese Rechenaufgabe auf dem Quantencomputer ausführen.
- Sie mussten nachweisen, dass das Endergebnis der Rechnung höchst wahrscheinlich korrekt ist.
- Sie mussten nachweisen, dass diese Rechenaufgabe von keinem herkömmlichen Computer in angemessener Zeit durchführbar ist, nicht einmal von den schnellsten Supercomputern.
-
Von allen diesen Aufgaben war die Erste mit Sicherheit die Schwierigste.
Googles Team formiert sich
Seit mehreren Jahren sammelte Google im Bereich Quantencomputer Erfahrung und gründete im Jahr 2013 das Team „AI Quantum“, geführt von dem deutschen Informatiker und langjährigen Google-Mitarbeiter Hartmut Neven. Zuvor war Neven bereits führend am Google Glass Projekt beteiligt.
2014 startete Nevens Team eine Koorperation mit dem bekannten Physiker John Martinis von der University of California, Santa Barbara. Er sollte den Bau eines neuen Quantencomputers leiten. Martinis Gruppe ist führend im Bau von Qubits auf Supraleiterbasis. Das Team sammelte zunächst viel Erfahrung mit einem 9-Qubit Quantencomputer und beschloss dann dieselbe Technologie auf einen wesentlich größeren Quantencomputer zu skalieren.
Im Frühjahr 2018 gab Martinis Gruppe bekannt, dass ein Quanten-Überlegenheits-fähiger Quantencomputer mit dem Namen „Bristlecone“ im Testbetrieb war. Google bezifferte die Größe von Bristlecone auf sagenhafte 72 Qubits! Zu diesem Zeitpunkt besaß der größte Quantencomputer gerade mal eine Größe von 20 Qubits.
Einen solchen gewaltigen Entwicklungssprung hätte wohl niemand für möglich gehalten. Sie erinnern sich: Ein Quantencomputer verdoppelt sein Potential mit jedem zusätzlichen Qubit. Zumindest auf dem Papier besäße Bristlecone damit das 1000 Billionen-fache an Leistungsfähigkeit.
Zu diesem Zeitpunkt schien es schon so, als ob der Nachweis der Quanten-Überlegenheit kurz bevor stehen würde.
Googles Quantencomputer „Sycamore“
Es wurde danach allerdings ruhig um Googles Ambitionen. Zwar baute Google weiter seinen „Stack“ aus und veröffentlichte die Programmierschnittstelle „Cirq“ für die Fernsteuerung von Quantencomputern auf Python-Basis. Außerdem erarbeitete das Team um Neven und Martinis eine Reihe interessanter, wissenschaftlicher Ergebnisse zum Quanten-Hardwarebau und zu Quanten-Algorithmen (teilweise verweise ich in anderen Artikeln darauf). In Sachen Quanten-Überlegenheit gab es aber zunächst nichts Neues.
Einen kleinen Eindruck von den Hardware-Problemen, mit denen Googles Team in dieser Zeit wohl zu kämpfen hatte, erhält man in Alan Ho‘s Vortrag auf der Konferenz „Quantum For Business 2018“ im Dezember 2018 vii, in dem der Google-Mitarbeiter die anderen Hersteller unter anderem zu einer engeren Kooperation aufruft.
Vielleicht aufgrund dieser „Durststrecke“ beschloss das Team wohl irgendwann ein Downsizing von Bristlecone vorzunehmen. Der neue Quantencomputer bekam den Namen „Sycamore“ und besitzt eine Größe von 53voll funktionsfähigen Qubits, die schachbrettartig auf einem Chip angeordnet sind. Der Quantencomputer wird nahezu bis auf den absoluten Temperatur-Nullpunkt herunter gekühlt. Erst dadurch werden die 53 nichtlinearen Schwing-Schaltkreise des Chips supraleitend und „kondensieren“ zu Qubits mit echten Quanten-Eigenschaften.
Die „Quanten-Gatter“, die elementaren Operationen des Quantencomputers, erzeugt Martinis Gruppe über Mikrowellen-Strahlung. Sycamore ist in der Lage die Quanten-Gatter auf jedes einzelne Qubit über eine externe Steuerelektronik auszuführen, die bei Zimmertemperatur arbeitet. Für die Kalibrierung der einzelnen Quanten-Gatter verwendete Googles Team dieselben Prüfroutinen, die auch für den Nachweis der Quanten-Überlegenheit zum Tragen kamen (mehr dazu weiter unten).
Um die Kopplungen unter den Qubits herstellen zu können, benötigt ein Quantencomputer generell zusätzlich jeweils ein Zwei-Qubit-Quanten-Gatter.
In einem Quantencomputer sind hierfür normalerweise gewisse Gatter mit dem Namen „CNOT“, „CZ“ oder „iSWAP“ vorgesehen, die Qubit B nur in Abhängigkeit vom Zustand im Qubit A verändern. Die Gruppe um John Martinis wählte hierfür einen anderen Weg: Die Forscher passten neue, quasi gemischte Gatter speziell auf die reale Physik von Sycamore an. Über eine Lernalgorithmen ermittelten sie dabei den entsprechenden Mischungsgrad für jede einzelne 2-Qubit-Kopplung.
Die Rechenaufgabe: „Random Quantum Circuit Sampling“
Bereits mit dem 9-Qubit-Quantencomputer sammelte die Gruppe um John Martinis Erfahrungen mit einer sehr speziellen Rechenaufgabe, die als aussichtsreicher Kandidat für den Nachweis der Quanten-Überlegenheit in Frage kam viii.
Die Grundidee zu der Aufgabe ist eigentlich ziemlich naheliegend und geht auf Richard Feynmans Grundgedanken zurück, der überhaupt zur Entwicklung der Quantencomputer führte: Gehen wir einmal davon aus, dass ein herkömmlicher Computer ein reines Quantensystem ab einer gewissen Größe nicht mehr simulieren bzw. berechnen kann. Das würde insbesondere auch bedeuten, dass ein herkömmlicher Computer bestimmte Quantenprogramme auf einem genügend großen Quantencomputer nicht mehr simulieren kann. Diese Quantenprogramme müssten nur hinreichend komplex sein, um sicherzustellen, dass das Problem nicht irgendwie Supercomputer-tauglich vereinfacht oder zerlegt werden kann.
Der einfachste Weg dies zu erreichen sind völlig zufällig ausgewählte Qubit-Operationen auf zufällig ausgewählten Qubits. Also ein Quantenprogramm, das durch reinen Zufall zusammengewürfelt wird. Am Ende der Zufallsrechnung werden alle Qubits ausgemessen und eine Reihe von Nullen und Einsen, also eine Bit-Reihe, ist das Ergebnis der Rechnung. Indem die Messung mehrmals hintereinander für dasselbe Quantenprogramm wiederholt wird, ergibt sich eine Liste von Bit-Reihen. Irgendwann wird die Liste so lang, dass sich einzelne Reihen verschieden oft wiederholen. Die Wiederholungen sind zwar zufällig, sie sind aber nicht gleichverteilt! Genau diese unterschiedlichen Häufigkeiten, mit der die verschiedenen Reihen gemessen werden, charakterisiert gerade das jeweilige Quantenprogramm.
Das Verfahren nennt sich „Random Quantum Circuit Sampling“. Die Idee ist so einfach wie genial, die Durchführung natürlich eine Herkulesaufgabe. Warum diese Berechnung für herkömmliche Computer so schwer ist, erläutere ich Ihnen übrigens nochmal ganz am Ende dieses Artikels.
Traurigerweise erhalten wir am Ende nur Reihen von zufällig ausgewählten Nullen und Einsen. Leider total nutzlos!
Oder wer würde sich schon für völlig zufällige Bit-Reihen interessieren?
Höchstens vielleicht die Webseite www.random.org.
Moment mal!
Wieso zum Henker gibt es eigentlich eine Seite wie random.org?
Ein reales Anwendungsgebiet: Quantenzertifizierte Zufallszahlen
So oder so ähnlich stellte der bekannte Computerwissenschaftler Scott Aaronson von der University of Texas, in der ihm unnachahmlichen Weise, sein Protokoll für „quantenzertifizierte“ Zufallszahlen im Jahr 2018 vor. Aaronson überraschte die Fachwelt mit einem Vortrag über das Sampling von Zufallsschaltungen ix. Darin skizzierte er sein Protokoll, das speziell für die erste Generation von Quanten-Überlegenheit-fähigen Quantencomputer zugeschnitten ist.
Es stellt sich heraus, dass verlässliche Zufallszahlen tatsächlich von Wert sind.
Von erheblichem Wert.
Zufallszahlen sind für viele Algorithmen und für viele Bereiche in der Informatik essentiell wichtig: Insbesondere für die Kryptographie. Nicht zuletzt durch den NSA-Skandal wurde offensichtlich, dass kompromittierte Zufallszahlen für die Übertragungssicherheit ein reales Problem sind. Aaronsons quantenzertifizierte Zufallszahlen besitzen die erstaunliche Eigenschaft, dass diese nachweislich echte Zufallszahlen sind, selbst wenn das erzeugende System unsicher und der Herausgeber nicht vertrauenswürdig ist.
Das Herzstück von Aaronsons Protokoll ist gerade die Tatsache, dass die Häufigkeit, mit der eine bestimmte Reihe von Nullen und Einsen vorliegt, einer Quantenverteilung gehorchen muss. Diese Verteilung, so argumentiert Aaronson, kann ab einer gewissen Reihen-Größe nicht mehr simuliert oder manipuliert werden. Sie kann nur noch von einem genügend großen Quantencomputer verifiziert werden. Danach wissen wir, dass die Bit-Reihen geradewegs aus einem Quantencomputer stammen und dann müssen es wirklich echte Zufallszahlen sein. Manipulation ist dann tatsächlich ausgeschlossen, weil ein Quantencomputer halt immer echte Zufallszahlen liefert. Sie werden weiter unten nochmal sehen, was ich damit meine (beim Stichwort „XEB-Routine“).
Um einen Eindruck davon zu bekommen, welche Anwendungsgebiete sonst noch in Sycamore schlummern könnten, können Sie übrigens meinen Artikel „Anwendungen für Quantencomputer“ lesen.
Das Finale: Googles Nachweis der Quanten-Überlegenheit
Aber kommen wir endlich zum eigentlichen Kern dieses Artikels.
Google hatte also endlich einen geeigneten Quantencomputer betriebsbereit, der verlässlich genug funktionierte, um die eigentliche Aufgabe zu bewältigen. Eine geeignete Rechenaufgabe hatte das Team ebenfalls ermittelt. Jetzt ließen die Wissenschaftler Sycamore gegen die besten aktuellen Supercomputer antreten.
Zunächst reduzierte die Gruppe um Martinis und Neven die schachbrettartige Anordnung der Qubits auf verschiedene, deutlich kleinere Ausschnitte und ließen den Quanten-Algorithmus laufen. Diese Vereinfachung verfeinerten sie weiter, in dem sie zusätzlich einfache Kopplungen zwischen mehreren Ausschnitten auf dem Qubit-Schachbrett zuließen. Die Liste von Bit-Reihen, die sie so erhielten, verglichen sie mit einer Quanten-Simulation auf einem einfachen herkömmlichen Computer, der die verkleinerte Rechenaufgabe noch bewältigen konnte.
Dafür verglichen die Forscher die Häufigkeit mit der ein einzelnes Bit-Muster im Quantencomputer ausgemessen wurde mit der Häufigkeit, mit der dasselbe Bit-Muster über die Simulation gemessen wurde. Für dieses Benchmark-Verfahren hatten sie bereits zuvor eine spezielle Prüfroutine entwickelt (mit dem schillernden Namen „Cross Entropy Benchmark Fidelity“, kurz „XEB“). Diese XEB-Routine ist so konzipiert, das selbst kleinste Abweichungen in der Häufigkeit große Abweichungen im Benchmark-Ergebnis liefern.
Tatsächlich stimmten die Benchmark-Ergebnisse aber überein.
Dann vergrößerten sie die Ausschnitte auf dem Qubit-Schachbrett nach und nach und wiederholten ihren Vergleich. Schnell wurde die Aufgabe für normale Computer zu aufwendig. Das Team musste Rechenzeit in Googles enormen Datacentern beantragen x.
Zusätzlich ließ das Team eine komplette 53-Qubit-Simulation laufen aber mit vereinfachten Quanten-Schaltungen und verglichen diese wieder mit den Ergebnissen auf Sycamore.
Wieder stimmten die Benchmark-Ergebnisse überein.
Irgendwann müssen sie weitere Hardware miteinbezogen haben: Hier kommt wieder der Supercomputer am Forschungszentrum Jülich ins Spiel, den sie in ihrem Aufsatz auch erwähnen. Am Ende bezogen sie sogar den größten aktuell existierenden Supercomputer mit ein: IBMs „Summit“-Supercomputer im Oak Ridge National Laboratory in den USA. Für die Simulation der Quanten-Rechnung benutzten sie verschiedene „State-Of-The-Art“ -Simulationsverfahren für Quanten-Systeme.
Am Ende zeichnete sich ein deutliches Bild ab.
Bis zu gewissen Ausschnitt-Größen konnten die Supercomputer die Simulation durchführen und kamen zu den gleichen Benchmark-Ergebnissen wie Sycamore. Für größere Ausschnitte konnten sie die Rechenaufgabe nicht mehr bewältigen. Die Quanten-Berechnungen selbst hatten dabei eine Komplexität von bis zu 1113 Ein-Qubit Gattern und 430 Zwei-Qubit Gattern (Sie können sich vorstellen, dass es zu diesen realen Schaltungen noch einiges zu erwähnen gäbe xi).
Um so eine Quanten-Berechnung auf allen Qubits auszuführen und die Qubits eine Millionen mal auszulesen, mit einer Millionen zufälligen 53-Bit-Reihen, benötigte Sycamore 200 Sekunden. Dabei entfiel der Großteil der Zeit auf die Steuerelektronik. Die Rechnung auf dem Quanten-Chip benötigte tatsächlich nur 30 Sekunden.
Für die Simulationen andererseits extrapolierte Googles Team die Rechendauer der vereinfachten Rechenaufgaben auf das gesamte 53-Qubit Schachbrett und kam am Ende zu folgendem Ergebnis:
Die untersuchten Supercomputer hätten für die volle Rechenaufgabe eine Laufzeit 10 000 Jahren benötigt!
„quod erat demonstrandum“
(was zu beweisen war)
Was ist nun mit IBMs Einwand?
Nachdem Googles Vorabversion der Arbeit an die Öffentlichkeit gelangt war, hatten diverse Forscher die Möglichkeit sich mit dem Aufsatz zu beschäftigen. IBMs Forschergruppe für Quantencomputer tat genau dies … und zwar sehr intensiv:
In bester wissenschaftlicher Manier entwickelten sie ein Gegenargument, das Googles Ergebnisse zumindest in Teilen entkräften sollte. Natürlich nicht ganz uneigennützig, denn in Sachen Quantencomputer hatte ihre Gruppe bis zu Googles Veröffentlichung die Nase weit vorn.
Ich will hier einfach mal wiedergeben, was Scott Aaronson, der mit den quantenzertifizierten Zufallszahlen, dazu zu sagen bzw. zu schreiben hat. Nicht nur war er von der Fachzeitschrift „Nature“ für die Prüfung von Googles Arbeit beauftragt gewesen, er ist insbesondere auch ein viel beachteter und interessanter Wissenschaftsblogger xii.
IBM hat vermutlich bewiesen, dass Googles Quantensimulation nicht optimal war. Ihr verbessertes Simulationsverfahren hätte für die Rechenaufgabe mithilfe ihres Supercomputers „Summit“, im Oak Ridge National Laboratory in den USA, nicht 10 000 Jahre, sondern 2 ½ Tage benötigt. Was natürlich ein gewältiger Sprung ist! Und man kann sich das Aufstöhnen von Googles Team in ihrem Gebäude in Santa Barbara (Kalifornien) vorstellen, als ihnen klar wurde, diese Simulations-Alternative übersehen zu haben (tatsächlich hatte John Martinis die Möglichkeit einer besseren Simulation in der Arbeit ausdrücklich erwähnt).
Man muss allerdings Folgendes bemerken:
Der „Summit“ ist ein Supercomputer-Schlachtschiff XXL auf einer Fläche so groß wie zwei Basketballfelder. IBMs Verfahren, das die Gruppe noch nicht ausgeführt sondern hochgerechnet hat, würde die gesamten 250 Petabytes = 250 Mio Gigabyte Festplattenspeicher von Summit benötigen, das Hauptargument ihres verbesserten Verfahrens xiii,und einen gigantischen Energiehunger besitzen.
Googles Sycamore ist im Vergleich dazu eher ein „Schränkchen“ (und das auch nur wegen der ganzen Kühlaggregate). Und nebenbei, selbst mit IBMs Simulation wäre Googles Quantenalgorithmus um einen Faktor 1100 mal schneller (zeitlich). Wenn man anstelle der zeitlichen Dauer die Anzahl von einzelnen Rechenschritten (bzw. FLOPS) vergleicht, wäre Google sogar um einen Faktor 40 Milliardenmal effizienter.
Und auch das IBM-Team leugnet nicht, dass selbst ihr Verfahren einen exponentiellen Aufwand für die Aufgabe besitzt und Googles Quantenalgorithmus eben nicht. D.h. wäre Google in der Lage Sycamore mal eben ein paar zusätzliche Qubits zu spendieren, würde man schnell die wahren Kräfteverhältnisse erkennen: Mit 60 Qubits würde IBMs Verfahren vermutlich 33 Summits benötigen, mit 70 Qubits müsste man eine ganze Stadt mit Summits füllen, …
Aaronson vergleicht diesen wissenschaftlichen Wettstreit mit den Schachpartien zwischen dem Großmeister Gary Kasparow und dem Computer „Deep Blue“ (ironischer Weise übrigens vom Hersteller IBM) Ende der 1990er Jahre. Die besten etablierten Kräfte können im Rennen eventuell noch eine Weile mithalten, bald sind sie aber weit abgeschlagen.
Warum kein Supercomputer diese Berechnung durchführen kann
Das „Quantum Circuit Sampling“ ist übrigens auch ein wunderbares Beispiel um zu verdeutlichen, welchen „Quantenvorteil“ ein Quantencomputer gegenüber herkömmlichen Supercomputern bei solchen Berechnungen hat:
Im Laufe der Berechnung werden die Mess-Wahrscheinlichkeiten der einzelnen 53-Bit-Reihen teilweise weiter verstärkt oder weiter unterdrückt. Am Ende kommt eine charakteristische Häufigkeitsverteilung heraus. Wie könnte ein herkömmlicher Computer solche Aufgaben lösen?
Stellen wir uns dazu ein sehr einfaches und naives Computerprogramm vor, dass sich jede Bit-Reihe zusammen mit ihrer jeweiligen Häufigkeit in einer Tabelle im Arbeitsspeicher merkt. In jedem Programmschritt beeinflussen sich jetzt die verschiedenen Tabelleneinträge gegenseitig, mal mehr und mal weniger.
Wie viele unterschiedliche 53-Bit-Reihen kann es geben? Diese Frage hört sich zunächst harmlos an, die Anzahl ist aber tatsächlich astronomisch hoch: Etwa 10 Millionen * Eine Milliarde, eine Zahl mit 16 Nullen vor dem Komma!
Ein herkömmlicher Computer benötigt weit über 100 Millionen Gigabyte Arbeitsspeicher, um soviele 53-Bit-Reihen zusammen mit ihren Häufigkeiten in Speichervariablen abzulegen … Wie viel Arbeitsspeicher hat übrigens Ihr Computer? 8 Gigabyte, vielleicht 16 Gigabyte? (Schon mal nicht schlecht!)
In jedem Schritt, von insgesamt 20 Schritten, überarbeitet Googles Programm die Messhäufigkeiten jeder Bit-Reihe. Diese hängen im Extremfall jeweils von den Messhäufigkeiten aller Bit-Reihen aus dem vorangegangenem Programmschritt ab. Das wären also 1 Mrd * 1 Mrd * 1 Mrd * 100 000 Abhängigkeiten, eine Zahl mit 32 Nullen vor dem Komma! Wie viele Sekunden würde ein herkömmlicher Computer vermutlich brauchen, um so viele Abhängigkeiten auch nur einmal anzufassen? Als Vergleich: Ein normaler Prozessor kann etwa eine Hand voll Milliarden Operationen in der Sekunde durchführen … und unser Universum ist nicht einmal 1 Mrd * 1 Mrd Sekunden alt.
Ein herkömmlicher Computer wird von so vielen Möglichkeiten und Abhängigkeiten also förmlich erschlagen. Ein Quantencomputer wiederum braucht dafür lediglich diese 53 Qubits und die knapp 1500 Einzelschaltungen. Unglaublich.
Auf den ersten Blick ist übrigens auch klar, dass die Quantensimulationen von Google und IBM, wesentlich ausgefeilten gewesen sein mussten als unser naives Beispielprogramm.
Nebenbei: Die Strategie der exponentiellen Komplexität verfolgen auch weitere Algorithmen für Quantencomputer der NISQ-Ära: Z.B. für die Quanten-Chemie, für Optimierungsprobleme oder für Quanten-Neuronale Netze (dort spricht man von „Variational Quantum Algorithms“). Das „Random Quantum Circuit Sampling“ ist der Kandidat, bei dem dies jetzt als erstes auch erwiesenermaßen zu einem exponentiellen Erfolg führte.
Ein verpasster „Mond-Lande-Moment“ für Googles Team?
Ohne Zweifel war der wissenschaftliche Paukenschlag auch als medialer Paukenschlag geplant. Zwischendurch wurde Google dann durch die Ereignisse überholt, was irgendwie nicht verwundert, wenn man bedenkt, wie viele Personen eingeweiht waren.
Am Ende soll das die Leistung von Googles Team nicht schmälern: Die Gruppe um John Martinis und Hartmut Neven hat mit ihrem Nachweis der Quanten-Überlegenheit wohl Technik-Geschichte geschrieben.
Scott Aaronson schrieb dazu bereits Ende September in seinem Blog xiv:
„The world, it seems, is going to be denied its clean “moon landing” moment, wherein the Extended Church-Turing Thesis gets experimentally obliterated within the space of a press conference … Though the lightning may already be visible, the thunder belongs to the group at Google, at a time and place of its choosing.“
Fußnoten
i https://www.fz-juelich.de/SharedDocs/Pressemitteilungen/UK/DE/2019/2019-07-08-quantencomputer-fzj-google.html: Pressemitteilung vom Forschungszentrum Jülich über die Zusammenarbeit mit Google
ii https://drive.google.com/file/d/19lv8p1fB47z1pEZVlfDXhop082Lc-kdD/view: „Quantum Supremacy Using a Programmable Superconducting Processor“, der 12-seitige Hauptaufsatz von Googles Team. Dieses Dokument stand kurzzeitig auf der NASA Webseite. Den 55-seitigen Zusatzaufsatz mit allen Detailinformationen (den „supplementary information“) finden Sie über https://drive.google.com/file/d/1-7_CzhOF7wruqU_TKltM2f8haZ_R3aNb/view. Ein paar interessante Diskussionen zu dem Aufsatz finden Sie auf Quantumcomputing-Stackexchange https://quantumcomputing.stackexchange.com/questions/tagged/google-sycamore
iii https://www.nature.com/articles/s41586-019-1666-5: „Quantum Supremacy Using a Programmable Superconducting Processor“, der endgültig veröffentlichte Artikel von Google
iv https://arxiv.org/abs/1203.5813: wissenschaftliche Arbeit von John Preskill „Quantum computing and the entanglement frontier“, der den Begriff „Quanten-Überlegenheit“ prägte. Die Wortwahl wurde zwar allgemein übernommen aber aus offensichtlichen Gründen immer wieder kritisiert. In seinem kürzlich erschienen Gastkommentar auf Quantamagazine geht er nochmal darauf ein https://www.quantamagazine.org/john-preskill-explains-quantum-supremacy-20191002/.
v https://de.wikipedia.org/wiki/Church-Turing-These#Erweiterte_Churchsche_These: Die Erweiterte Church-Turing-These besagt, dass sich zwei universelle Rechenmaschinen in allen Fällen gegenseitig effizient simulieren können (genauer gesagt: Mit nur „polynomialem“ Rechenaufwand).
vi https://de.wikipedia.org/wiki/Br%C3%Bcder_Wright#Der_Weg_zum_Pionierflug: Wikipedea-Artikel über die Wright-Brüder und ihre Pionierarbeit für die Luftfahrt.
vii https://www.youtube.com/watch?v=r2tZ5wVP8Ow: Vortrag „Google AI Quantum“ von Alan Ho auf der Konferenz „Quantum For Business 2018“
viii https://arxiv.org/abs/1709.06678: wissenschaftliche Arbeit von John Martinis et al „A blueprint for demonstrating quantum supremacy with superconducting qubits“
ix https://simons.berkeley.edu/talks/scott-aaronson-06-12-18: Vortrag „Quantum Supremacy and its Applications“ von Scott Aaronson zu seinem Protokoll für „quantenzertifizierte“ Zufallszahlen.
x https://www.quantamagazine.org/does-nevens-law-describe-quantum-computings-rise-20190618/: Artikel auf Quantamagazine, den man als Ankündigung für Googles Nachweis interpretieren kann. Darin wird übrigens auch „Nevens-Law“, eine Quantencomputer-Variante von Moores-Law, erwähnt: Darin geht Hartmut Neven von einer doppelt-exponentiellen Steigerung der Quantencomputer-Entwicklung aus.
xi Googles Team wählte für die zufälligen 1-Qubit-Schaltungen einen speziellen Satz von Quanten-Gattern, der möglichst klein war aber trotzdem „simulationsfreundliche“ Schaltungen vermied. Näheres dazu in https://quantumcomputing.stackexchange.com/questions/8337/understanding-googles-quantum-supremacy-using-a-programmable-superconducting-p#answer-8377. Die 2-Qubit-Schaltungen waren in Googles Experiment tatsächlich nicht zufällig ausgewählt, sondern folgten einer festgelegten Reihenfolge, die sich aber anscheinend auch wieder als nicht-simulationsfreundlich erwies: https://quantumcomputing.stackexchange.com/questions/8341/understanding-googles-quantum-supremacy-using-a-programmable-superconducting-p#answer-8351. Auch wenn sich diese Kopplungen wiederholten: Unterm Strich bleibt Googles Qubit-Schaltung eine zufällige Schaltung.
xii Scott Aaronson‘s aktuellen Blogeintrag https://www.scottaaronson.com/blog/?p=4372, in dem der Forscher zu IBMs Gegenargument Stellung bezieht.
xiii https://www.ibm.com/blogs/research/2019/10/on-quantum-supremacy/: Blogeintrag zu IBMs verbesserten Simulationsverfahren: Google war davon ausgegangen, dass man für eine verbesserte Simulation einen Supercomputer mit einem astronomischen RAM-Bedarf benötigen würde. Da so ein Rechner nicht existiert, wählte Google ein ungünstigeres Simulationsverfahren, das den fehlenden RAM mit einer längeren Laufzeit kompensiert. IBMs Hauptargument ist nun, dass Summit zwar nicht über solch einen astronomischen RAM, dafür aber über astronomischen Festplattenplatz verfügt. Deshalb könne auch das günstigere Simulationsverfahren verwendet werden.
xiv https://www.scottaaronson.com/blog/?p=4317: „Scott’s Supreme Quantum Supremacy FAQ!“ Blogeintrag von Scott Aaronson zum Nachweis der Quanten-Überlegenheit. Nebenbei ist seine gesamte Webseite eine Goldgrube für jeden, der mehr über Quantencomputer erfahren will (und wie Sie hier sehen können, von mir entsprechend oft zitiert).